
AI/머신러닝을 통해 High-Content 세포 분석에서의 도전과제를 극복하세요.
인공지능(AI)은 자율주행 자동차에서부터 음성 어시스턴트와 예술 작품 창작에 이르기까지 현대적 삶의 여러 측면에서 발견할 수 있습니다. But it’s the application in science and healthcare where the benefits of AI really stand out. One of these applications is in bioimage analysis or high-content analysis (HCA).
As HCA has matured and gained wider adoption as a quantitative tool for biomedical research, the application space continues to grow and is no longer limited to a finite list of well-defined assays performed in standard biological models. To account for this added complexity, a large focus has been placed on improving the flexibility and performance of analysis methods through AI or machine learning. In fact, there are many examples where it outperforms traditional methods for applications across many scientific disciplines.
Up until recently, the use of these more sophisticated machine learning methods have been largely reserved for research groups that have adequate access to specialized skills in data science and custom software development. Here, we provide a brief introduction to AI and explore how emerging, turnkey machine learning software solutions are enabling researchers to leverage all content in an image and perform a more comprehensive analysis, while removing the burden of complexity for the user.
What is AI or machine learning?
Machine learning is a form of AI (artificial intelligence.) Deep learning. Neural networks. These are all slightly different terms for AI, which the Oxford dictionary defines as:
“The theory and development of computer systems able to perform tasks normally requiring human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.”
Essentially, AI represents any intelligence demonstrated by machines that mimics cognitive functions we would usually associate with human minds such as learning, problem solving, and reasoning. Machine learning is technique used by scientists to allow computers to quickly learn from data.
Overcoming the complexities of a HCA workflow
At its core, a high-content screening or HCA workflow, like our ImageXpress Confocal HT.ai is nothing more than automated microscopy followed by automated image analysis. During the acquisition stage, images are acquired from multiple samples in microtiter plates. This can involve collecting a vast amount of image data if you're trying to understand, for example, an efficacious drug to rescue some diseased phenotype.
The analysis portion of the workflow can be broken down into two parts—image analysis and downstream analysis. During image analysis, certain features and measurements are extracted from the image and converted into a format in which statistical analysis can be applied. Downstream analysis involves taking all of the high dimensional data and distilling it down to a format that scientists can interpret and draw conclusions so that they can proceed to the next phase of their research project.
Today’s world of high-content screening is much more comprehensive when it comes to understanding and describing a phenotype. Instead of extracting a single feature or taking a ratio of some different measurements, researchers are extracting thousands of features for every cell within an image. This doesn't require that they know what the target is for a drug or that they fully understand the function of a gene. It is simply looking for differences between two different conditions by leveraging all the information rich content within the image.
As the complexity of certain assays continues to increase and as we extract more information from an individual cell, the data becomes even more overwhelming. So how do we make sense of all this information and distill it down to something that is actionable?
Traditional image analysis methods can be especially intricate and time consuming when performed manually or even semi-automatically. There’s always the possibility of human error and bias due to the difficult and extremely detailed nature of the task. 여기에 실험과정이 반복적이고, 시간이 오래 걸리며, 종종 노동력이 많이 소요되는 속성이 있다면, 머신러닝을 적용할 수 있습니다. AI removes any person-to-person variation, human error, and bias, thereby improving data quality and confidence as well as optimizing workflow and efficiency.
Overcoming human bias
One of the key benefits of machine learning in HCA that deserves special note is the ability to overcome human bias. When studying large data sets, humans are vulnerable to a well-described phenomenon called ‘inattentional blindness’. This is where unexpected observations go unnoticed when performing other attention-demanding tasks.
For example, having previously studied a particular cell phenotype and response in detail, you might be unintentionally looking for those same signs when presented with a large, complex data set containing many variables and measures. In doing so, you might then overlook another subtle or unexpected feature that also has biological relevance.
Machine learning helps overcome this vulnerability, performing completely unbiased classification, with the potential to produce unexpected, valuable findings.
Applying machine learning to object segmentation
Reliable quantitative data is vital for every downstream step in the HCA workflow, with segmentation being the first. Segmentation is the process of extracting the objects of interest (e.g., organelles) from images and then quantifying their features. Basically, it’s the first step in converting image pixels into numerical data.
Segmentation can be challenging, especially when working with traditional signal processing methods, which are designed to focus on one object. In microscopic images of cells or tissues, objects are typically crowded or clumped together. What’s more, they have different sizes and shapes. There is often the issue of poor signal-to-noise, low contrast, and poor image resolution. Not to mention, there can be high phenotypic variability due to chemical perturbations or natural heterogeneity in the cell type itself.
To address the challenges of segmentation, deep learning algorithms can be applied to the image analysis portion of the HCA workflow. As an example, IN Carta™ Image Analysis Software includes a deep learning-based module called SINAP that is designed to work with a wide range of data.
Because SINAP uses deep learning, it can account for large amounts of variability in sample appearance that arise from the test treatments under investigation. By ensuring that each treatment is segmented with an equivalent level of accuracy, the information extracted in this step can be reliably used to compare treatments in subsequent steps of the analysis.
Examples of IN Carta SINAP module in use:
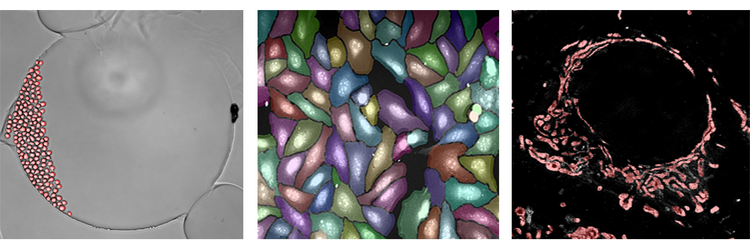
Above are examples of the SINAP deep learning algorithm being applied to three completely different sets of data. Brightfield analysis is depicted in the far left figure. The analysis is really single-cell segmentation over time, watching live cells divide and move around. The middle figure shows segmentation of a Cell Painting assay. Even though the cells are crowded, SINAP is able segment the objects with high accuracy. Lastly, the figure on the far right is from a super resolution image of mitochondria. Once again, even though this content is completely different, the same workflow and algorithm can be used to study individual mitochondria in the data sources and image. In all three instances, you are able to more accurately and reliably complete segmentation with ease using the SINAP deep learning algorithm.
Applying machine learning to object classification
Because you are trying to leverage as much content as possible in a HCA workflow, it is important to ensure that the content has some degree of quality before reaching the downstream analysis step. This is where object classification comes into play. Object classification is the process of dividing up data sets into sub populations based on phenotype (e.g., cellular morphology, sub-cellular localization, expression level of specific markers).
It is possible to use a classifier tool to manually pick relevant features and assign classes, but this is only applicable to straightforward phenotypic changes based on a few measures. For example, you might be determining a cell cycle stage based on nuclear dye intensity or classifying live or dead cells in a viability assay. For anything more complex involving an expanded set of features, the use of AI for object classification becomes a better option.
With machine learning, the human user no longer has to manually select measures or thresholds. Instead, this task is assigned to the computer. The human user provides the computer examples of different classes of cells. The computer figures out how to differentiate between those classes. In essence, the computer is learning the most appropriate features and has the extra advantage in that it can learn the right combination of features.
IN Carta software also includes a trainable object level classifier module called Phenoglyphs. The Phenoglyphs module uses the information extracted by SINAP to group objects having a similar visual appearance. 이를 통해, 치료제가 유리한 표현형을 만들어 내는지 평가할 수 있으며 관련된 기본 메커니즘을 추론할 수도 있습니다. 머신러닝을 사용하면 모든 시각적 기능을 동시에 분석하여 객체를 올바른 그룹에 할당하는 데 필요한 복잡한 규칙 집합을 최적화할 수 있습니다. This highly multi-variate and data driven approach is far more capable of resolving subtle phenotypic differences and is more robust against assigning objects to the incorrect group.
The four steps of training the IN Carta Phenoglyphs module:
- Cluster: The module automatically selects and uses measures calculated during segmentation to create natural groupings in the data, called clusters, without human bias.
- Label: The user selects and labels all valid classes (at least two) for ranking and training.
- Rank: The module ranks the list of measures used to partition objects into classes and provides the opportunity to deselect measures with redundant information or little impact.
- Train: The module refines the classification model based on user input, including removal of objects or reassignment to more appropriate classes.
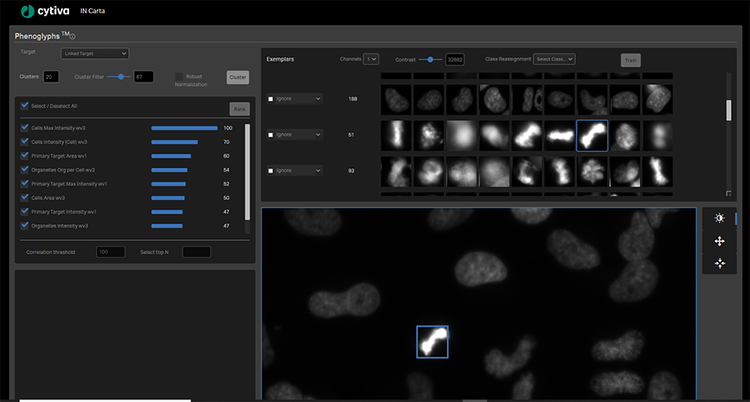
Training the Phenoglyphs machine learning classification module
사용자는 Phenoglyphs 모듈이 전체 데이터 세트에 모델을 적용하기 전에 각 분류에 대한 소수의 예시를 검토하고 이를 입력하기만 하면 됩니다. This approach minimizes the need for user input at the first step of class assignment, thus saving considerable time.
Removing the guesswork
Unique to IN Carta software is the initial unsupervised step that is built into both SINAP and Phenoglyphs modules. The unsupervised step generates an initial result that is iteratively optimized simply by having the user confirm or correct the algorithm’s decision. This removes the burden of determining a viable starting point for the analysis and eliminates the need to tweak parameters in a tedious trial and error fashion. By combining SINAP and Phenoglyphs, users experience an end-to-end workflow that requires no prior experience in image or statistical analysis and is streamlined for shorter time to results.
Learn more about optimizing your HCA workflow with machine learning. View our IN Carta software page.